IA Generativa y algunos desafíos poco evaluados
Hay ciertos riesgos en el uso de la IA Generativa que a mi modo de ver no se están dimensionando adecuadamente, y que plantean grandes desafíos.
En el último año hemos visto como el concepto LLM y la IA Generativa de ser términos de nicho y muy de computines, se han transformado en conceptos de uso cotidiano y recurrentemente citados en los medios de comunicación, producto de una adopción masiva, como lo muestran múltiples estudios. En la gráfica siguiente se muestra el porcentaje de la «población conectada» que está utilizando IA Generativa (encuesta realizada por Salesforce) en diferentes países, el porcentaje de la India es bastante llamativo en todo caso, (el artículo no describe en detalle la metodología utilizada).

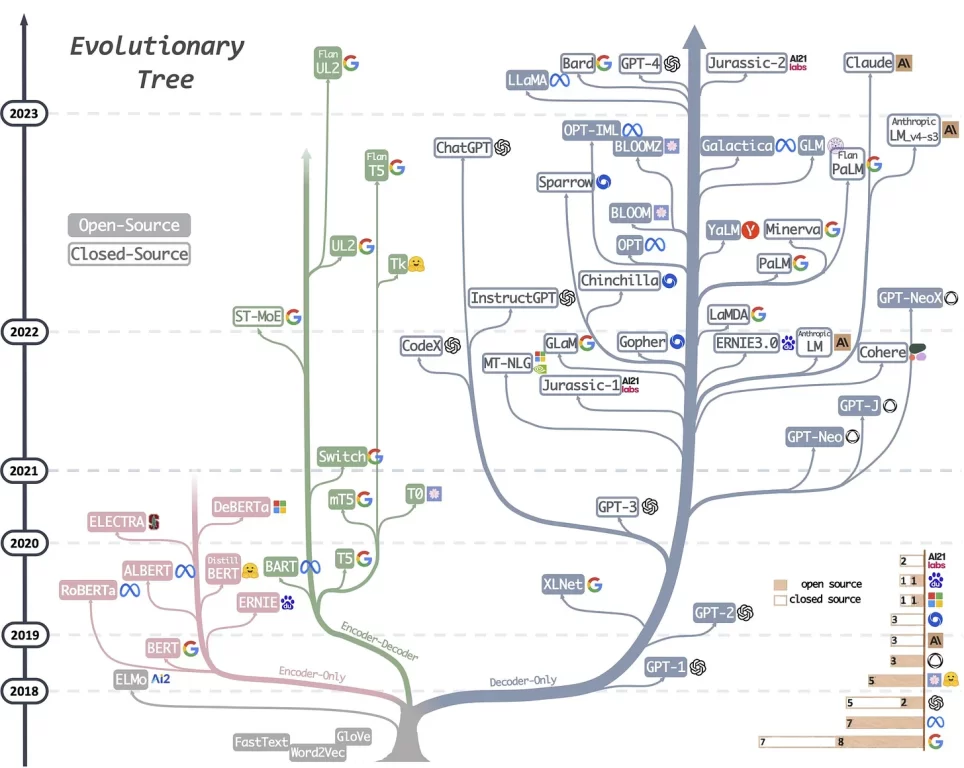
La IA Generativa y todas sus componentes han pasado desde espacios acotados de discusión, a grandes debates en diferentes ámbitos, desde el mundo político, pasando por el ámbito económico , llegando hasta el área judicial. Así mismo, la evolución y crecimiento de toda un industria, en una carrera casi desenfrenada por generar más y mejores modelos, como lo muestra el siguiente árbol genealógico del desarrollo de modelos del tipo LLM (que tomé prestados desde aquí), que involucra a todas las grandes tecnológicas y otros actores.
{kind=link}
¿Palos de ciego?
La mayoría de los países, están desarrollando políticas públicas al respecto, y los desafíos regulatorios no son menores.
Hace un par de días, el presidente de los Estado Unidos emitió una Orden Ejecutiva, la cual era esperada hace ya tiempo, que busca dar ciertas directrices en materias de regulación de la IA. En dicha orden algunas afirmaciones plantean serias dudas respecto de su implementación, por ejemplo:
“In accordance with the Defense Production Act, the Order will require that companies developing any foundation model that poses a serious risk to national security, national economic security, or national public health and safety must notify the federal government when training the model, and must share the results of all red-team safety tests.”
Algunos expertos, tal es el caso de Gary Marcus, han planteado bastantes dudas de como se va a implementar esto.
Pero no se queda ahí, plantea como mecanismo de control de los contenidos automáticos, el uso de sellos de agua (watermarking) lo cual como lo plantean algunos medios de prensa e investigadores de la Universidad de Maryland, tienen serios problemas no es la bala de plata.

En la Unión Europea, ya cuenta con bastante avances y un marco regulatorio inicial. Recientemente fue más lejos e impulsó en el marco del G7 un acuerdo sobre los Principios Rectores Internacionales de la Inteligencia Artificial (IA) y un Código de Conducta voluntario para los desarrolladores de IA en el marco del proceso de IA de Hiroshima (acuerdo anterior logrado en Japón en 2023).
Localmente, muchos de nuestros países están avanzando en esto, algunos en forma decidida y otros a trastabillones, pero si podemos decir que pocos han ignorado el tema.
Tres riesgos no del todo visualizados
Más allá de estos avances, hay algunos riesgos que no veo del todo dimensionados en estas discusiones, ni en estos procesos regulatorios, ni en el diseño de políticas públicas:
- Uso de contenidos sin autorización, la IA generativa, como se está desarrollando actualmente es más “un toma todo, con poco o nada a cambio”. Las empresas de IA utilizan el contenido en forma gratuita para entrenar sus modelos y en consecuencia potenciar su negocio, a cambio de nada, ni siquiera tráfico a los productores de esos contenidos. Ya existen múltiples acciones legales en torno a esto, y de prosperar, los desarrollos de IA van a recibir un golpe de donde menos se esperaba.
- Vacas Locas, hoy el incremento de generación de contenidos sintéticos, está generando que el conjunto de datos de entrenamiento contengan este tipo de contenidos. Los modelos actuales se entrenan, sin saberlo, con cada vez más datos sintéticos de IA. En la medida que esto aumente, y los modelos de IA Generativa utilicen datos producidos por esos mismos modelos, se podría producir lo que se llama Autofagia del Modelo (MAD), análogo a la enfermedad de las vacas locas en el largo plazo.
- Bosque negro u oscuro, algunos han planteado que este proceso de masificación de contenidos generados por algoritmos, redundará en un alejamiento de los seres humanos. Las capacidades (volumen) de generación de contenidos sintéticos es tan alta, que difícilmente podremos competir, y finalmente los contenidos de la web serán mayoritariamente generados por bots, algoritmos y/o algún software basado en Inteligencia Artificial, lo cual de seguro va a alejar a generadores de contenidos “menos automáticos”.
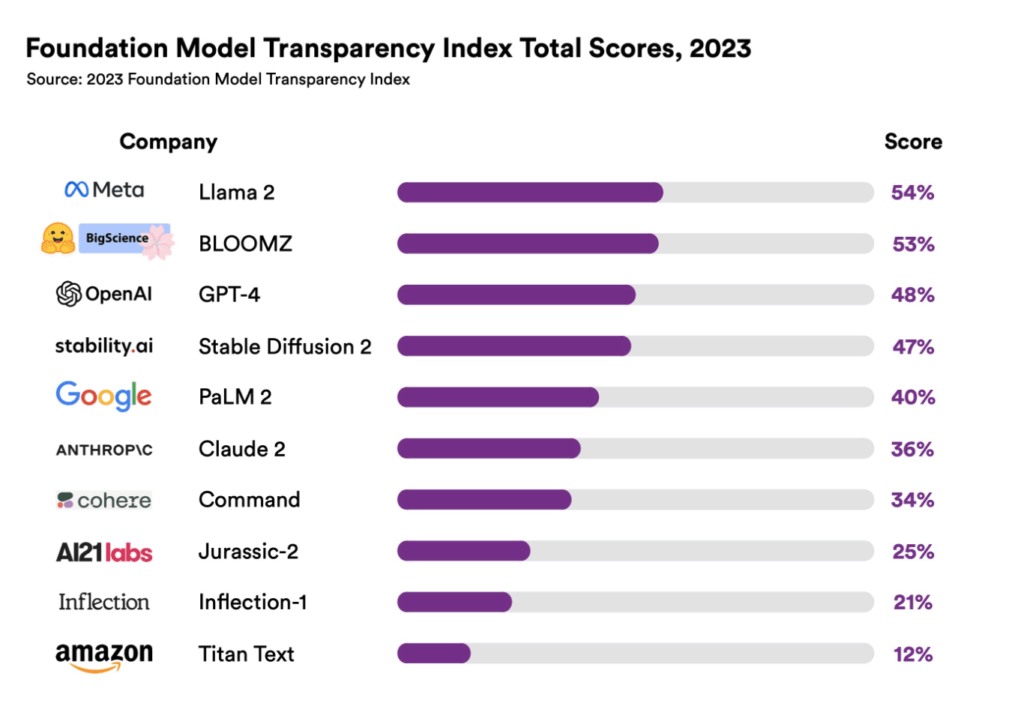
Algo que no ayuda a esto es la falta de transparencia de muchos de estos modelos, tal como lo demuestra el estudio de de la Universidad de Stanford, me refiero al The Foundation Model Transparency Index, en cuyo índice los modelos más transparentes sólo llegan el 54% en un rango de 1 a 100.
Es de esperar que las normativas que están surgiendo, permitan abordar de mejor forma estos desafíos.
Xi, China, y Biden, USA, en APEC 2023,han comentado, según información periodística, que la IA, no se usará en drones y armas nucleares, qué opina?
Y les crees?
Saludos
Alejandro